Agile Infrastructure
May 25, 2014 1 Comment
By now, you’ve probably figured out that agile is this new-agey style of software development. But agile is far more than just group hugs and stand-ups. By that I mean, agile is more than a project management system. Agile is a way of managing change and being able to respond quickly to it, whilst delivering as much value to the customer as possible.
How do we achieve that? It certainly isn’t possible just because we’ve planned our sprints. Agile goes all the way down to the code base (or starts at the code base, depending on how you look at it).
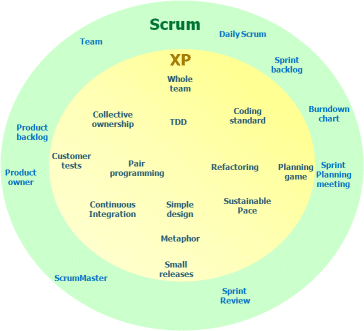
Scrum is a project management system which deliberately ignores the technical practices required to engineer good software. It shows you which item will deliver the next chunk of value to the customer, whereas eXtreme Programming, or XP, is a set of technical practices which mostly ignores project management. XP’s set of good engineering principles tell you how to produce quality software. Combining the two is very common, as you then know what to work on next and then how to go about delivering it in a quality manner.
I like to call Scrum without the supporting technical practices “Hollow Scrum” because I imagine this picture (Scrum / XP) with the insides missing. Without the technical insides, agile will actually hurt your productivity. You will be lying to yourselves about “doing agile” and you will start blaming agile for not delivering the increased efficiency promised, even though it was you who broke the contract.

Over the years, we have developed and re-appropriated some tools to enable agile development and aid you to use the Technical Practices to maximum effect. Warning: It is entirely possible to use one or all of these tools and still not be agile. I don’t believe that is possible to claim to be Agile without this basic infrastructure. Your code and project will suffer greatly without it.
As a warning, I am going to use the word “Mainline” a lot, because it’s the language we use at Tait. This is the equivalent of trunk, default or master, depending on which version control system you use.
Version Control
When working in an agile context, version control takes on a new role. One of the goals of agile is to release early and often. One cannot deliver often to many different customers without some sort of tool tracking exactly what code was in each release. Maintenance is something you probably haven’t needed to deal with too much yet. Right now, if you find a bug, you’ll just fix it and include that in the next release and everything’s fine.
But what happens when you find a major security flaw? How do you tell your customers whether they’re affected or not? How do you release to an extremely conservative customer who absolutely needs a particular bug fixed, but doesn’t want to take on the risk of any other development that you’ve done in the meantime? This is one of the battles we face every day at Tait. Most of our customers are very conservative with their software choices, so a large part of what we’re trying to do is solve their individual needs whilst keeping the number of active releases of software to a minimum.
As part of releasing our software, we have a couple of different branching strategies, all geared towards slightly different requirements. On the Terminals team, the 30-odd developers all pour their changes into the mainline, and they cut a release branch to stabilise in preparation for unleashing it on the world. This is because they want the speed of 30 developers’ worth of change for the upcoming release, whilst avoiding having the teams go off in completely different directions.
In the Applications team, my current team, we treat the Mainline as the permanent release branch and cut separate branches to do each sprint on. Once the sprint is delivered, it gets merged back to the Mainline and we start a new one. This means that we can release at a moment’s notice, pulling in carefully selected changes from the sprint branch as necessary.

Version control is important for helping use to achieve this. It also comes with these other benefits:
- Gives you a restore point if you decide your current changes aren’t going to work (which should happen in a functioning agile team!)
- Enforces and enables automatic source-level integration in a team, so you all end up with the same code at the end of the day.
- Helps to show you when two people are stepping on each other’s toes. When a file collides frequently and often, this leads to us taking a moment to see what can be done about it. It might be the version control giving us a design hint, or that we need to change how we work. But too many conflicts is often the thing that prompts the discussion.
- Has branches for isolation. A Release branch as I previously mentioned or a Feature Branch, which is isolating the development of a feature from the rest of the team. In my team, this is used only as a last resort, when the feature’s likely to touch a large number of files and/or keep the build broken for an extended or unquantifiable length of time.
- A log of decision-making in the commit comments. Someone on my team wrote “fixed a bug” as their commit earlier this year. We named and shamed such behaviour. In 2 weeks time, when my fast-aging memory has failed me, I don’t care that you fixed a bug, that’s written in your job description. I want to know why you fixed it, and what behavoural affects it might have on the code, so when I’ve found a new bug later and I’m scrolling through the commit log in the hopes of easily seeing the cause, I can discount your obviously perfect code.
- Allows for searching of history
- finding where a bug was introduced will often give clues for how we might fix it.
- Can easily discover and talk to the original implementer of a particular feature about design considerations when trying to extend their work.
- Can discover which versions of software are affected by certain bugs (you know, like heartbleed)
When I first joined Tait, we were using CVS and it probably caused about as many problems as it solved. We had to write a bunch of wrapper scripts and a server-side database for checking in, such that it was at least vaguely usable, but we did make it work for us. We’ve since moved on to mercurial in the Terminals and Applications teams. If Tait can move on to a modern version control system with a 15 year old code base and custom infrastructure, without losing any history, then anyone can.
One Step Build
The One Step Build is a fairly simple concept. With only the click of the metaphorical go button, developers should be able to build the software in exactly the same way as it is when deployed to the production environment.
- Manual steps are bad. Humans are inherently prone to human error. If one step takes long enough for a dev to move on to something different, then there is a strong chance that they will forget it has happened and do it again. Or try to. Or break it by doing so. Or forget where they’re up to and miss a step. Or consciously skip a step.
- Even if it’s just for productivity reasons, having fewer steps from building to running code is a good thing. Basically, if you’re spending any time trying to do anything other than ‘hit the metaphorical go button’, you’re churning too much time on unnecessary, error-prone tasks.
- But it turns out the biggest reason comes down to pressure. When a release needs to go out the door yesterday then shortcuts will be taken. If that involves altering how you build and there’s a non-zero chance that you won’t get bit-for-bit identical builds out the other end, then the first thing you need to do before you release is start doing all your testing again, because the thing you’ve just produced is an unknown quantity. Your shortcut that saved you an hour just cost you two weeks and a lot of embarrassment when it didn’t work in some trivial way. Sometimes you’ll get lucky and everything will be okay, but humans are notoriously human. We forget things, we make mistakes. Let the machines do what they’re best at – following instructions to the letter each and every time.
When you are nearing your deadlines for this project, getting the build wrong and submitting something that is broken in obvious ways because you built it slightly differently under release pressure to how you did when testing / developing, will reduce your mark (I hope!). Having your build automated is one less thing to stress about when releasing your software.

That was one of the things that surprised me the most when I first joined Tait. The Terminals team did all of their release builds in a manual process. In my first week I was handed an instruction manual on four A4 sides of paper detailing how to do a build for release. It took me just four times doing the weekly build before I had a script in place to do the boring bits for me. Cutting the ceremony out of doing a build meant that the barrier to entry was lowered significantly and releasing no longer hurt like it used to. The next time the Apco Team were about to release, they were able to get release candidates daily.
But the one step build is slightly bigger than just a Larry Wall laziness feature. If the continuous integration shows that there is a problem, then always being confident that there is nothing special about the way the code is being built, makes reproducing those issues a whole lot easier. I’m not saying it eliminates them, because there can be other environmental factors as well. I have written and had to fix code that ran perfectly fine on my box, until it started running on the 12-core, multi-processor, massively parallel build server where my threads really were running simultaneously, meaning the tiniest windows of opportunity were reliably failing. And if the code is only failing on the build server, it can often be very hard to fix efficiently and the temptation is there to “just check in something quickly” and see if it worked. That’s not ideal and will likely hold everyone else up. It’s a good idea to have a bit of a think and, if you’re not confident you can fix it quickly, then you’re stopping the 29 other people from the opportunity to be shown the error of their ways.
Continuous Integration
On the first slide, I showed you a bunch of technical practices which all support agile. Continuous integration is more or less the parts of that picture which are able to be automated.
- Checking the latest round of code out of source control. This asserts that you didn’t forget to add a file and that everyone else working on it doesn’t have something that won’t even compile because of some silly error.
- building it in one step. Build servers by their very nature need to be automatic, so if you can get it working for them end to end, then you can get it going for your developers too!
- running the automated tests developed via the underlying technical practices (like test driven development)
- Reporting any failures and making them visible. If you’re building on every single check in, then it’s very straight forward to tell who broke it. The tests all passed on the previous build and now they don’t. J’accuse!
- Isolating defects in time. If unit tests are about isolating defects in space, or which area of the code, then isolating the defects in time gives you an extra axis with which to track it down.
Continuous integration is the glue that holds together the rest of agile infrastructure and makes things like TDD worthwhile. There is no point in writing tests if they never get run. Plus the only way to run them properly is to run them on any box that hasn’t been used for development. If there’s some environmental trick to getting the code to run, you can guarantee that every developer will have done it before lunchtime.

Oh, and then there’s that word integration. It turns out that writing code by yourself is relatively easy. Largely because you understand what you meant. Most of the time. But when you’re working with other people, you’re lucky if you understand what they mean even some of the time. When these mismatches of understanding occur in code, things don’t work as well as they should.
In a commercial setting, integration is a bit more complicated than textual conflicts in code. It’s also a problem of scale. There are a bunch of people, potentially multiple teams, working on the same product. They’re probably working in relatively separate areas of code, but at some point these two, or more likely, six, subsystems will have to function together to form said product. Integration is making sure that each function call works as the caller thinks it should, and that any side-effects are considered. Automated tests should explore these assumptions as best as they can, such that running them is a fairly decent indication of a correctly functioning program. Integration is hard[citation needed] because it tests our ability, as humans, to communicate.
Extreme Programming teaches us that if we find any particular task difficult, then we should do it more often or “Take it to the Extreme”. That way, if we’re agreeing with Larry Wall’s famous three virtues of a programmer, then we will soon find the pain points and codify them away. Therefore, we should integrate as often as possible, or continuously.
Whether or not you’re aware of it, every time you push code to a shared repository, you’re integrating. Your new code has to work with the existing code, so we should run the previously written tests along with the new tests that you’re sure to be checking in. This way, if some of your assumptions don’t hold or someone has changed the rules of a sub-system on you, then the continuous integration will tell you very early in the piece. You are never in a better position to fix the code you’re writing than while you’re still writing it. So as a second-best option, we’ll settle for minutes after you’ve finished. It’s still at least an order of magnitude better than even as far away as the end of the sprint.
The extreme other end is where every developer has a personal branch and you all pile your changes in at the end. If you are on a project where that is the case, I suggest you bring a sleeping bag along when everyone tries to merge, because you will be there forever trying to untangle that mess. Yes, I have wasted many hours of my life trying to integrate things from odd angles. Usually under time pressure.
It turns out that one of the secrets to a good continuous integration system is to keep the immediate build to less than 10 minutes. At this point in your coding lifetime, this probably seems trivial, but if you ever start working on a C program with thousands of files which have to all compile separately and link and then run the tests (which probably also needed to link separately), then it becomes a challenge.
10 minutes is a bit of a magic number, but mostly based on the fact that it will take you around 15 minutes to properly get immersed in a new task, so you won’t suffer needlessly from context switching if the build does fail. The code ideas should still be in your short-term memory and fixing it is probably still very cheap, relatively speaking.
The Next Step: Continuous Deployment
Once Continuous integration is really working for you, the next evolutionary step is continuous deployment. Continuous deployment only really makes sense in a web environment, where the application only lasts as long as a single request. This is quite a scary concept – having changes going live as soon as they’ve passed all the automated testing. You suddenly want to make very sure that your automated testing is up to scratch. My team are currently doing a very watered down version of that with the web app we’re developing.

We continuously deploy to our test environment. It means we’re getting some of the benefits forced upon us, in that assumptions about the cloud environment are tested (notably the SQL provider has stricter rules than that of our development machines) and our deployment is necessarily fully automated. If I can reference the last section again, it truly is a relief knowing that pressing the deploy button is going to work every time when we’re risking downtime for the customer, or more likely, the availability of our own weekend which might be spent fixing things such that the customer doesn’t notice when they arrive at work on Monday.
The problem of the broken mainline
So now you have your agile infrastructure in place, and someone checks in a change to the code which doesn’t compile or fails a test or “breaks the build”. The correct response is to fix that as soon as humanly possible. If you’ve been working on small chunks, with a solid set of tests around it, then that should be a relatively trivial affair. If you’re working on a large legacy code base written in C and your check in caused a test in a different part of the program to fail dramatically because you’ve exposed their reliance on a thread race or something equally difficult to sort out, then the problem changes somewhat.
All continuous integration systems that I have come into contact with have the built in assumption that the build success is a binary decision. Either everything worked perfectly or it is considered broken. This is a Good ThingTM as broken windows syndrome will creep in very quickly and more easily than you would ever imagine.

So it becomes the norm that the build is broken. Thus further breakages appear and go unnoticed (thanks to the binary all or nothing). So even if the original failure gets fixed, the build is still broken because of other reasons. This sort of thing really hurts productivity, to the point that my team has a light that switches on when the build is broken. This means that all team members and anyone walking past can see when the build is broken (and we do get people asking what it’s all about).
So now that the Team has decided that continuous integration helps their development, it becomes a question of Team Culture to keep the build light off, just as it was Team Culture allowing the broken windows. In order to keep the light off as much as possible, it becomes the top priority of the person who checked in the failing code (which the continuous integration system helpfully highlights for us) to get the light switched off as soon as possible. Other team members are encouraged to socially pressure the perpetrator and potentially help them to get it fixed, if need be. It shouldn’t be a pleasant experience, but we’re not out to make our developers cry.
The Applications team certainly isn’t the only team with such a mindset. Terminals have a notion of the person responsible for coordinating the fix. This rather large mouthful of a title is because they have a slow build turn-around, relatively speaking and they have the most developers working on the same code base and are more therefore more likely to suffer from multiple simultaneous breakages. This means that the first person to break it becomes responsible for getting it back to green, which usually amounts to checking the reasons for build failure quite closely and if it’s not their fault, then politely informing the person who did check in the break, that they need to look into it.
The infrastructure teams also do this sort of thing. There are many posters around their scrum boards with a doctored photo of the team lead reinforcing the social pressure in a light-hearted way that broken windows aren’t ok. (light-hearted is important when coming from a team lead!)

One of the examples of broken windows being seen as ok is within the former DSP team. They would compile their code with warnings turned off and the number of warnings grew and grew. This lead to the feedback loop suggesting that some of the terrible things they were doing were safe and a reasonable trade-off in the name of perceived efficiency. The number of bugs that would have been caught just by having compiler warnings as errors in this project is phenomenal. They more or less got away with it for so long because the DSP is a relatively small portion of the code base and is extremely parallel, with the majority of bugs showing as weirdness in the sound coming out of the radio or sound just not coming out at all. But wow, that’s such an expensive way to fix things.
The Problem of the “Special Mainline”
For a while in the Terminals Team at Tait, we had this habit of having an Apco Team Branch and an “everyone else” branch. The Apco Team would merrily do their development for months or even more than a year at a time and then try and merge the whole lot back into the everyone else Mainline. As you can probably guess, this didn’t work particularly well. Part of the reason for this was because we were using CVS at that time. CVS was the best tool of its time, but it’s not 1998 any more.
As a junior, I was semi-regularly tasked with tracking down when a particular bug was introduced and the number of times when I landed on a massive merge was dis-heartening. I often felt like I had failed, because even though I had tracked down when it happened, I wasn’t able to give any better information on how we might fix it. I no longer have such misgivings. There was a disproportionate amount of breakage in those merges, partly because we were using an inferior tool and partly because we thought it was a good idea to test inter-team communication for months at a time all at once.
When it was time to do one of those merges, we would often have a developer go dark for the better part of a week just trying to get it done. This is not a good way of doing software development – you will lose weeks at a time, without even being aware of it.
I liken it to two cars crashing into each other at high speed and in fact we would refer to them as ‘Big Bang Merges’. Two or more teams of people working on what started out the same, have now evolved their code into something that’s remarkably different. When those two objects which are no longer the same shape attempt to occupy the same space, the universe tries to correct this impossibility with explosive results. It’s much easier to grow the two code bases at the same time. It can often feel slower to develop software like this, but the alternative has the slow-down in a different place, and has the nasty side-effect where bugs can be introduced and go unnoticed more easily.

An agile board
Just to go a wee bit sideways here, in that the rest of the talk is about tools to get your code in order. The agile board is the one piece of infrastructure that really only exists in an agile environment. It needn’t be a fancy 60” touchscreen hooked up to the latest in Agile software. It might be a spare bit of wall with some post-its attached.

It’s very easy to underestimate the power of this piece of equipment
– Makes work visible
- Shows to yourselves when work is taking longer than it should. “It’ll be done by next standup” 3 days in a row.
- It is a nice feeling being able to see something physical moving across the board. Software is never finished and it’s very easy to forget what you’ve accomplished, so having a thing represent completion for you is reason enough to have it. Having that accomplished feeling is a good feedback mechanism for developing a rhythm of delivering on time.
- When it’s a web-based tool, it makes working remotely a bit easier. As someone who worked in the European timezone for around 6 months, I can tell you that it is a good start for communicating the bare minimum about who is working on what and what is available to pick up next. But if you’re all working in the same room, then the post-its are just as effective.
- It provides a bit of marketing to the rest of the company. If the big-wigs walk past and can see you’re doing something totally awesome, it helps them to think good things about your team when making decisions. In my experience, it doesn’t go the other way. They see even mundane work as “necessary”.
- It greases the wheels of a large company. Project Management can look at this board and see what’s happening right now without needing to interrupt the developers actually working on it. Or they can raise a task on the backlog, knowing that the developers will likely need to investigate it a bit more themselves before they are ready to have a proper conversation about it.
If you’re looking for Free Agile Software to use on your projects, then I recommend Trello
Conclusion
Version Control, Continuous Integration, and One Step Builds are parts of the agile infrastructure because they have some common themes. They allow us to respond more quickly to change, whether that’s change in the code, change in the requirements or a change in the thinking of a team member and they help us to oil the wheels of delivering value.
But the most important aspect of agile infrastructure is something that I’ve hinted at throughout the talk and that is Team Culture. If your culture allows broken windows, or code manufactured to bypass continuous integration (doesn’t have tests) or doesn’t allow the team to jump in to help someone who is struggling on a task that we all thought would take an hour and has ballooned to 3 days, then all the 60” touchscreens in the world won’t save your project from failing. Agile Infrastructure are some tools – it’s up to you to use them effectively.


I should point out – this was originally written as a Guest Lecture for a group of 3rd year students at university. Also, I’ve broken my rule of not changing it (except for typos / spelling mistakes, etc) after posting originally. This is because I will be giving the talk on June 5th, so I’ve been revising it and have added about 10% more content.
This post, now with 10% more awesome.